 Zabbix 下载
Zabbix 下载 Zabbix 手册
Zabbix 手册 Zabbix合作伙伴地图
Zabbix合作伙伴地图 成为我们的合作伙伴
成为我们的合作伙伴
 订阅系统登录
订阅系统登录案例|浙商银行Zabbix实践之路
Zabbix带来了哪些变化?
规范监控指标,集中展示告警,统一配置监控,减少页面卡顿、被监控对象丰富。
—— 张雯裕 浙商银行 金融科技部
本文整理自浙商银行张雯裕在2022Zabbix峰会演讲分享。ppt可在公众号后台回复“ppt".
1、浙商银行的ZABBIX实践
2016年浙商银行的规模相对较小,做对公业务为主,特点为:
1.单笔交易金额大
2.交易频率低。当时的IT设备少,运维人员也少。
当时的方式为:用发短信的接口来接收Socket协议,再将文本发送,对方便可发短信,运维人员在机器上写Shell脚本,DF执行,观察某盘超过80%,如超过则调用接口,将信息发出。
这种方式带来的问题是:工作量大、阈值调控过于频繁、容易出错。
在变更投产时,将告警停掉或注释掉时,常会关后未再启,之后如有故障发生,发现无报警,倒查后发现监控在某时被关掉。该方式是适应当时发展状况的。写Shell脚本是操作系统自带的,不会对操作系统装任何的agent等,安全性较高。
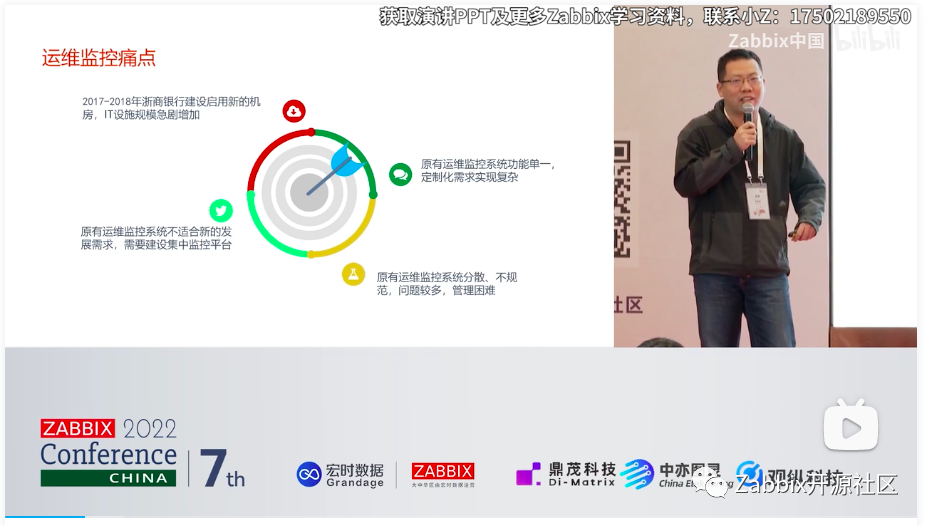
当时运维领导不希望在生产服务器上装任何东西。2018年浙商银行建设启用新机房,机房的规模变大了几十倍。目前生产服务器为5,000多台,故此不适用于监控脚本的方式,当时是急需建设一个监控平台。
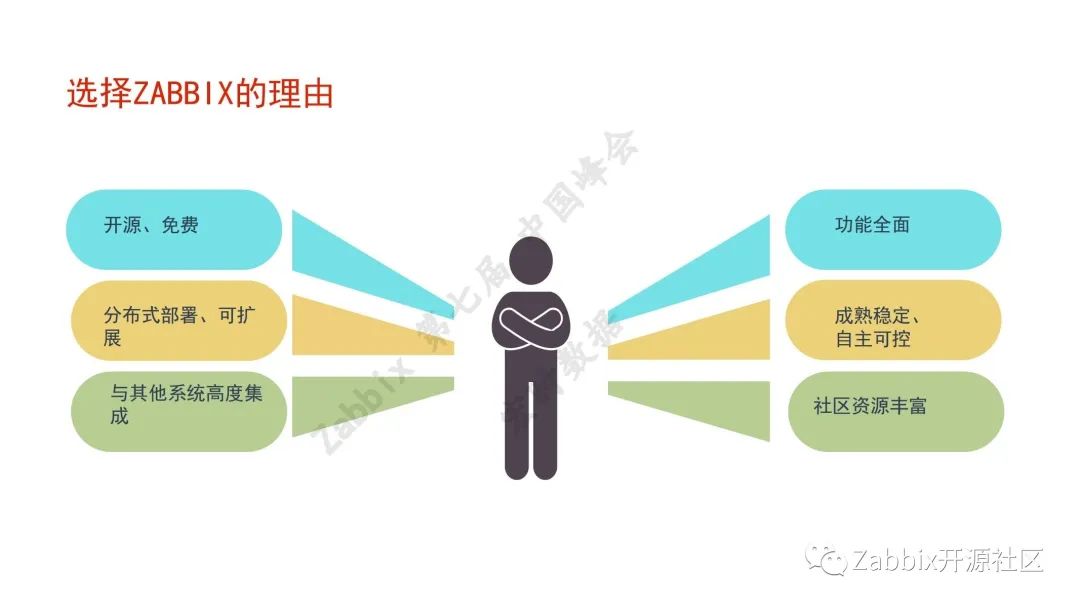
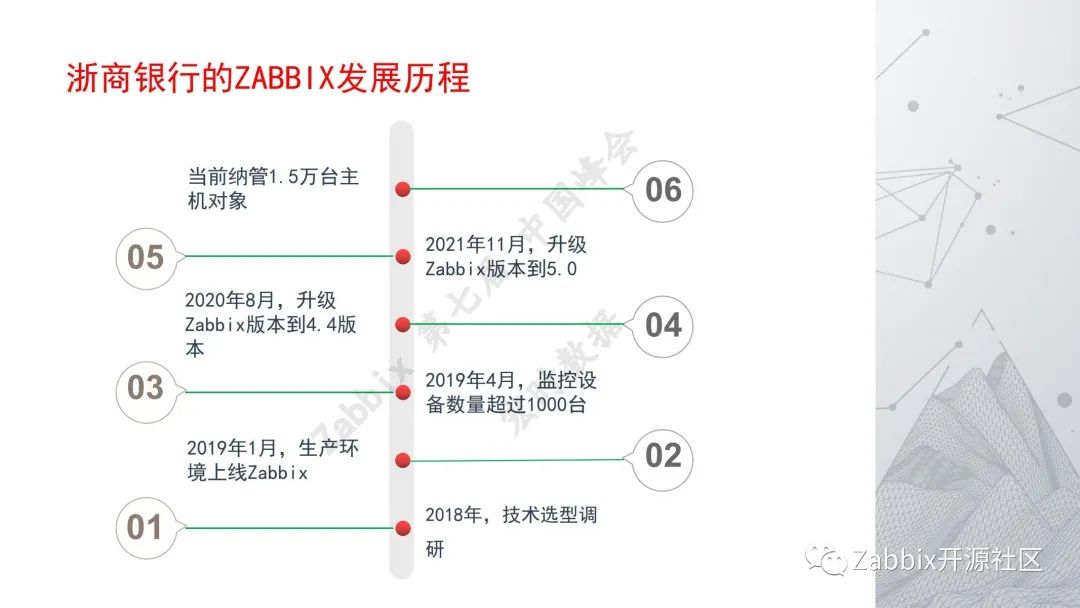
最终于2018年10月新机房启用,随后开始进行测试技术调研选型,于2018年底领导拍板决定可以试用Zabbix,2019年的1月,生产环境正式上线。刚上线时只选了不是很重要的系统来监控,逐渐推广,到2019年4月监控的设备数量超1,000台。
2020年8月考虑引入厂商支持,之前都是自己内部在使用,当时行内开始使用K8S容器云,我们自己做不了,随后根据厂商的意见,兼容K8S容器云,将版本升级到4.4。2021年11月,开发将容器云升级到5.0,目前浙商的Zabbix纳管主机已经超过1.5万台。

监控对象:操作系统、中间件、数据库、存储硬件、网络设备、容器云、定制化。无论是硬件、网络、应用、服务器,都在Zabbix监控范围内。浙商目前有1.5万个监控主机,130万个监控项,78万个触发器。至于Zabbix Server,浙商是一个Server多个proxy的形式,故此Server的压力较大,MVPs是1.1万。

Zabbix带来了哪些变化?
一.规范监控指标。写Shell脚本会出现方式、监控阈值制定或者风格的差异,如今已将指标都规范了。
二.集中展示告警。我们将Zabbix问题看板作为值班看板,将天旦BPC的告警、动环的告警、网络专用设备、存储设备的告警都通过Syslog或Kafka接到Zabbix作为统一的看板。
三.统一配置监控。主要是指管理方面,以前的告警由各系统去配置。后因Zabbix才有了统一的小组专门去配置监控,如此监控的质量就有了保证。
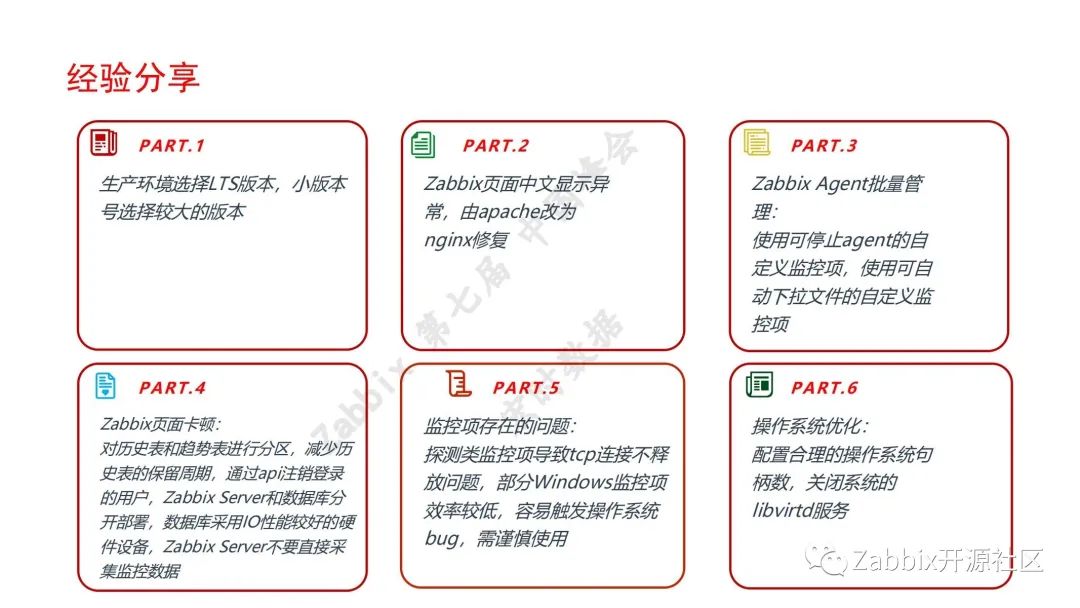
分享下在Zabbix在实践过程中踩过的坑。
由于早期没有厂商的支持,走了不少弯路,问题比较多,主要分享第四、第五部分。
四.页面卡顿。机器规模变大后,由于只有一套server,会很卡,表象为页面打不开,监控数据录不进数据库,从数据库层面看大量的MySQL都在历史表。
为解决卡顿问题采取了以下方法:
4.1 除了数据库方面的优化,对历史表、趋势表进行分区,历史表的保留周期,不建议大家保留的时间过长,例如:保留一个月或半个月还是有点长,前台人很多,查完历史数据,如果页面不关,后台会不停地刷新数据,导致锁表。
4.2 通过APR注销登录。卡顿时去数据库里查看登录的用户筛选ID,把所有用户全踢掉,卡顿问题立马解决。
4.3 Zabbix Server和数据库分开部署。所有的监控都由proxy去采数据,将极大地优化性能;Zabbix proxy扩展能力很好,但是性能瓶颈与数据库的IO有关,建议数据库采用IO性能更优越的硬件。
五.被监控对象问题。如探测类的监控项,通过Zabbix Server或者agent探测某个IP的某个端口。如果对面的应用有缺陷,Exception没有捕捉到异常,会出现连接不释放的问题。
5.1 如应用特别陈旧且书写不规范,会导致连接不正常,监控的请求没有正常关闭等,建议探测类的监控,大家做一下测试再部署。完全自己编写的软件反而要慎重。
5.2 Windows的操作系统,如Windows 2008,400多天不重启,也可能导致连接不释放,特别是Windows 2000,Windows2008,Windows 7,Windows Vista,Windows XP基本上都存在相同的问题。长时间不重启,如果都是长连接,连接不释放是没问题的,但监控是短连接,每采集数据便建一次连接,只要到BUG周期,系统就会挂,所以要特别注意。
Windows监控还有效率较低的问题,如数某个目录下有多少个文件,有时候会锁住文件,正常业务逻辑是以文件的形式发过来处理完再删掉,但出现过应用程序删不掉,监控时把文件锁掉,这种概率较小,把监控的频率调低,基本上就能解决。
2、浙商银行的运维监控体系
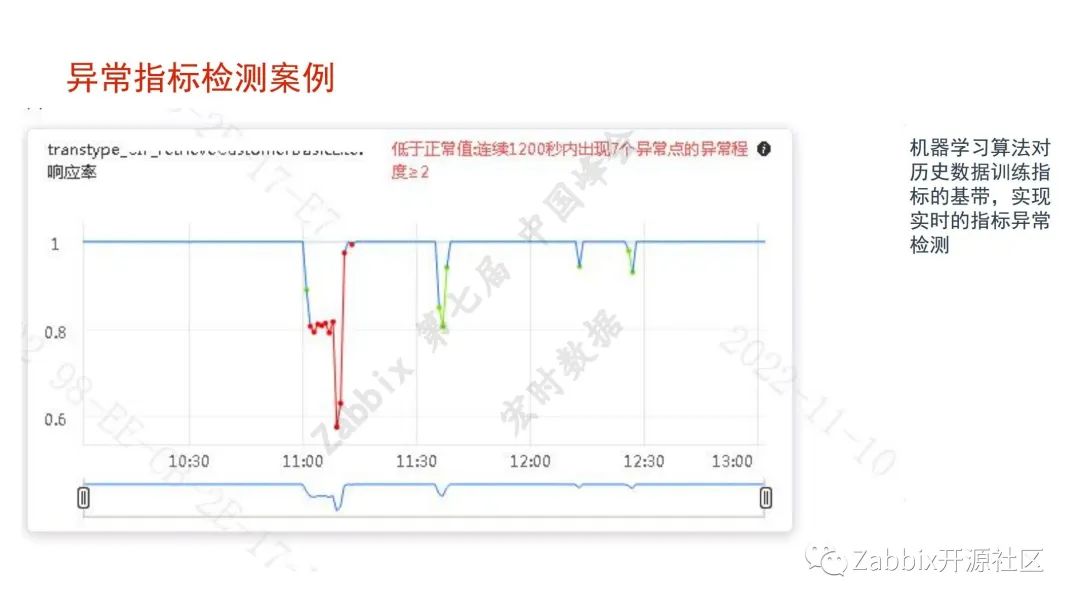
一.数据采集。通用类的监控用的是Zabbix,日志用的是Elk;专业领域如存储、机房动环、NPM、天旦的BPC、APM,听云等方案浙商都在用,采集数据做分析,主要是做异常指标检测,用智能分析的算法来做。
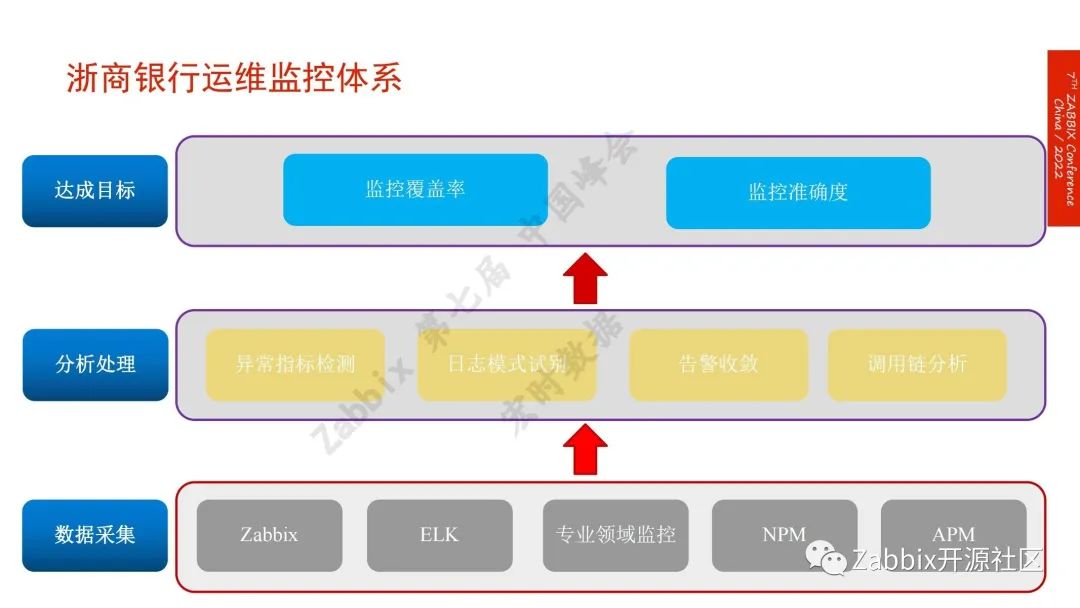
二.日志的模式识别,运维过程中日志经常报错,虽然报错,但不影响业务运行。如用户密码输错有时候写业务逻辑时,会归类到报错,使用自然语言把错误日志进行聚类。
如有新的类别或者是某一个错误字的类别数量增加,弹出告警,做告警收敛,调用链分析、告警收敛效果不是很好。最终我们希望尽可能提高监控的覆盖率。当有故障发生时,希望监控系统告警,而不是等着业务人员告诉我们系统不能使用。
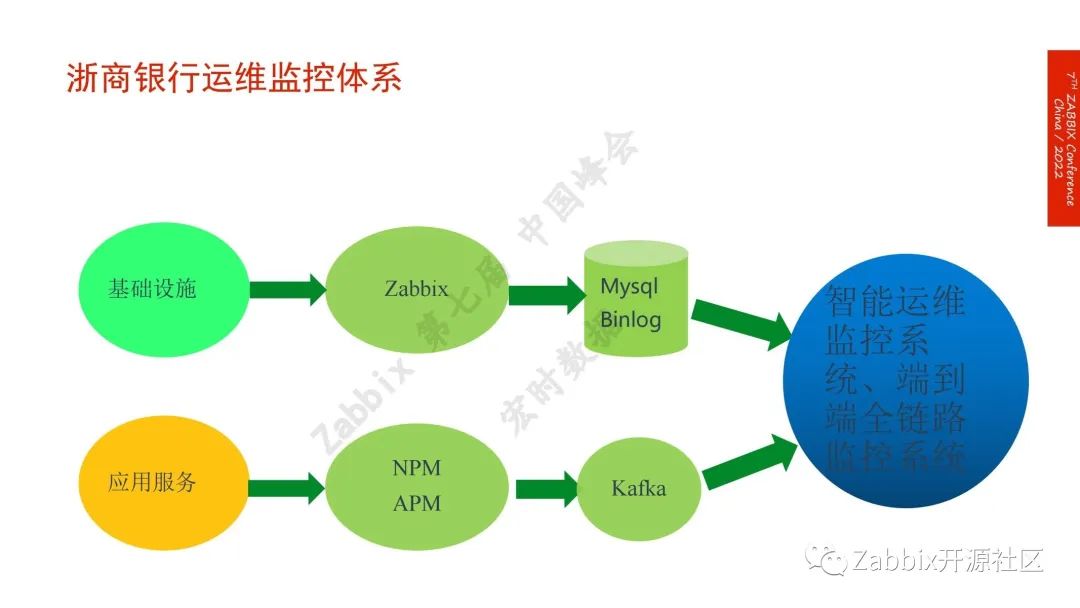
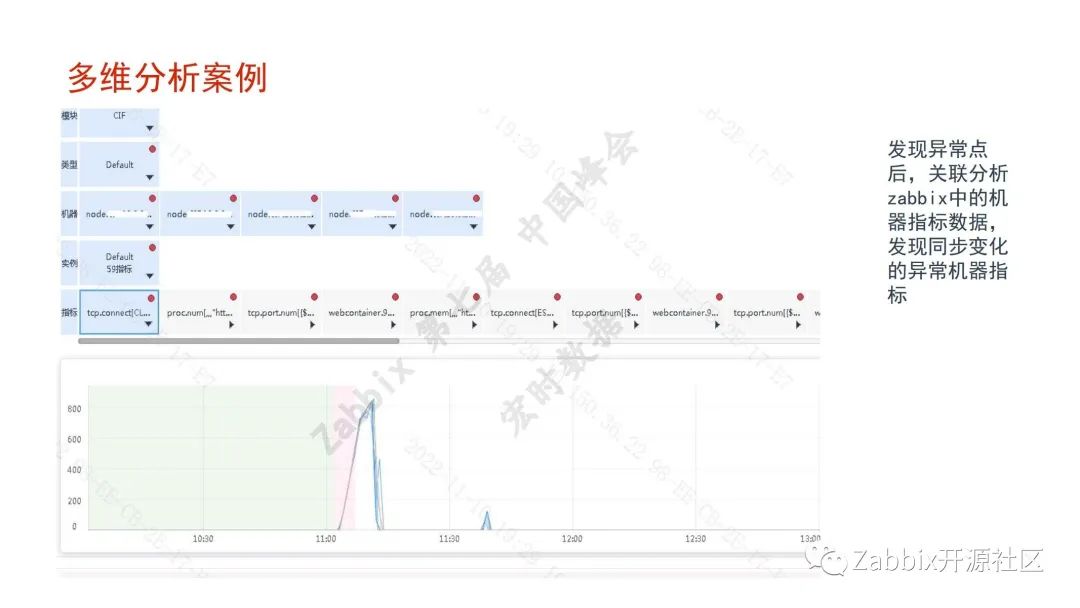
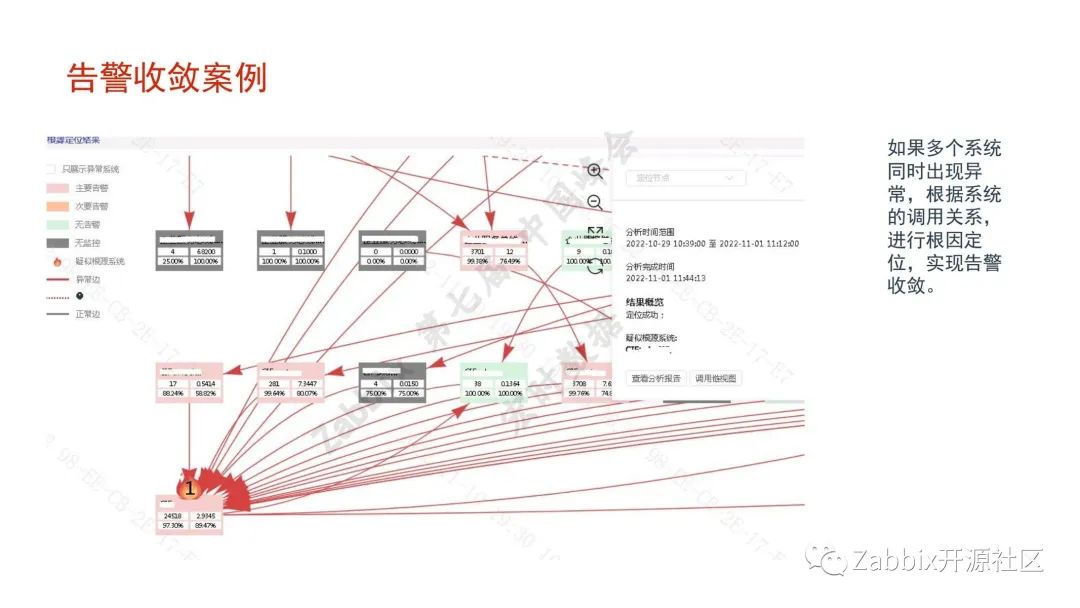
未来展望。Zabbix数据库的规模,目前有3T,历史数据的查询较卡,我们会考虑更换持续数据库、ES或者对Zabbix Server进行拆分,创始人表示Zabbix 7.0会支持多Server,我们非常期待该功能。浙商的容器云的规模也在开始大规模的推广,对容器云的适配后续考虑拓宽Prometheus的使用。
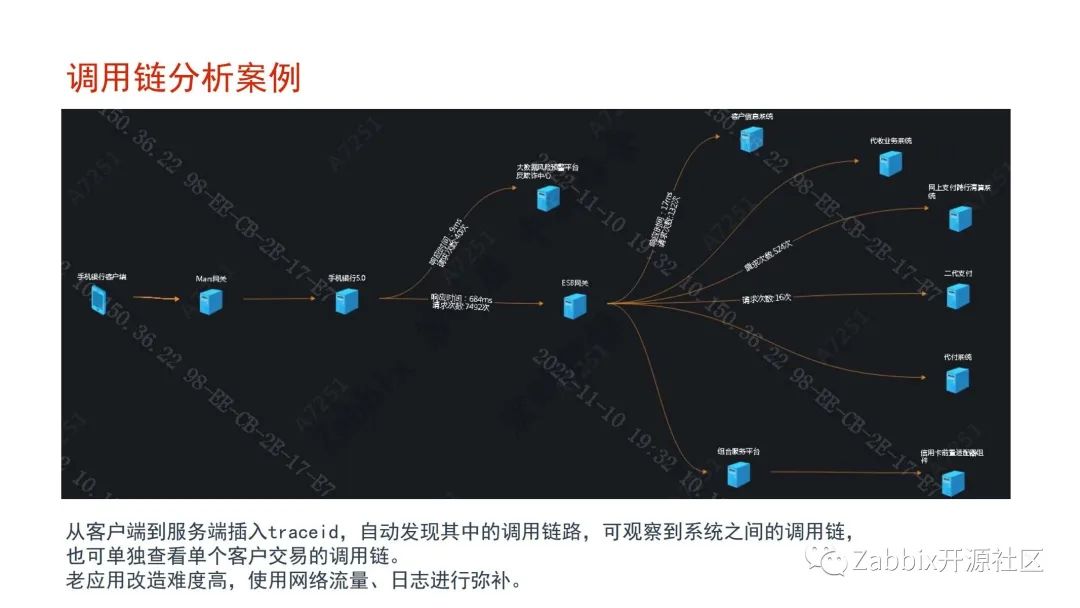

调用链的分析要牵扯到应用的改造,需要协调开发那边去修改代码,难度较大,我们希望逐步的扩大调用链分析的覆盖面,智能运营方面,我们希望能够做一下告警收敛,提升监控告警的准确度,我的演讲到此结束,谢谢。
扫一扫|加入技术交流群 微信号|17502189550 备注“使用Zabbix年限+企业+姓名” 5000+用户已加入!



一个人走得快,一群人走得远!
 2023-03-27
2023-03-27






