本文来自江苏电信智能云网调度运营中心张哲峰在Zabbix Meetup南京站的演讲,张哲峰也是Zabbix中文手册译者,感谢张哲峰对社区的大力支持!
云计算在江苏电信是一项比较新的业务,只有十几年的历史,不像核心网等传统通信业务,由一或几个厂家主导,可以提供一个非常完善的网管,因此云底层的监控天然具有解耦性。一路走来,从最初的人工巡检、写脚本执行定时任务,到采用的定制化网管商业产品。从17年左右,江苏电信开始积极拥抱开源,选择了Zabbix作为集中监控系统,最终融合江苏电信自研云运维平台——凌霄,成为监控的底层实现模块。Zabbix作为一款成熟的开源产品,在江苏电信的应用非常广泛。省管平台中的CT云,也就是我们部门负责维护的私有云,主要是底层硬件,共计10000+主机,是省内最大规模的监控;其次是IT云,以虚拟机监控为主,也有10000台以上的体量;除了云之外,Zabbix还承载了诸如核心网、数通等专业部门的通用硬件和业务系统约5000台的监控量。江苏电信的专业子公司,号百、智恒、全渠道,地市分公司维护的行业云、政务云以及一些自建的业务平台,也都应用了Zabbix进行监控。此外电信负责的一些客户项目,比如说华泰桌面云、苏果混合云,也选择了Zabbix作为底层监控系统。总而言之,Zabbix在江苏电信应用规模大、范围广,可以说是监控的中流砥柱。
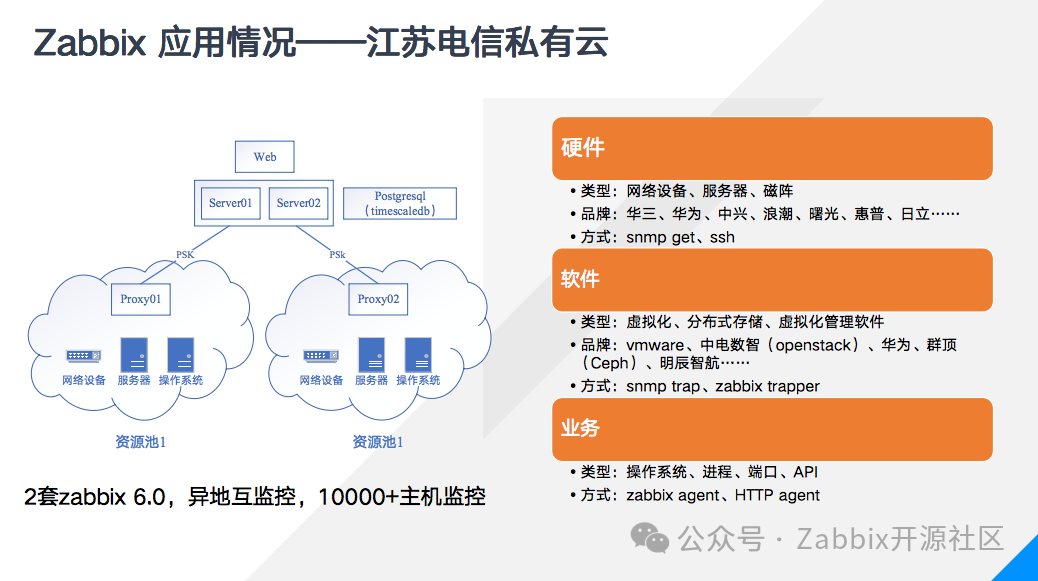
聚焦到我负责的私有云方面,去年完成物理机上云后,版本从4.0升级为6.0,采用的是docker部署的双server高可用架构,后端采用Postgresql+timescaledb的时序数据库插件,通过电信内网连接位于其他资源池的proxy。系统划分为两套,一套位于吉山数据中心,负责仪征资源池的监控,另一套位于仪征数据中心,负责仪征以外资源池的监控,两套Zabbix以agent和web拨测的方式相互监控。我们维护的云底层,硬件设备包括网络设备、服务器、磁阵等,涉及华三、华为、中兴、浪潮、曙光等,可以说几乎涉及所有主流厂商,硬件监控方式以snmp get方式为主,这是传统的网管协议,绝大多数产品都支持,不过具体监控效果就取决于厂家的的协议实现,此外有一些不支持snmp协议的老旧设备,我们用ssh监控方式通过运行脚本登录巡检的方式加以补充。在软件方面,主要涉及虚拟化软件,比如vmware的vsphere、中电数智,也就是电信自研的基于openstack的虚拟化产品,分布式存储,比如华为等厂商的存储软件,以上软件都支持snmp trap,先将告警发送至内部私网的proxy,再送至外部的server,此外还有一些软件的监控通过厂家开发的Zabbix trapper程序。除了软件硬件,我们内部的操作系统、零星的内部运维系统也会通过Zabbix agent监控,进行常规的端口、进程、自定义监控项,以及通过HTTP拨测业务API等。虽然Zabbix的功能强大,但是随着使用的深入也逐步发现一些系统之外的问题。随着资源池的增大,一次扩容动辄成百上千,手工添加监控已经人力所不能及,此外随着主机群组、用户、告警方式的增多,账号的权限、告警条件的设置都变得非常复杂容易出错,此时再指望完全由个人去维护监控就变得不太现实了。为了解决这些问题,我们将省内的云运维平台——凌霄平台与Zabbix结合起来,通过平台去管控监控的生命周期。凌霄平台主要做了两件事,第一是由CMDB保证资源的准确,通过调用Zabbix的API实现监控任务的下发,第二是Zabbix不直接调用告警系统,而是将告警汇聚至凌霄平台,由平台去做告警的预处理和订阅,确保派发策略的可见和统一管理。
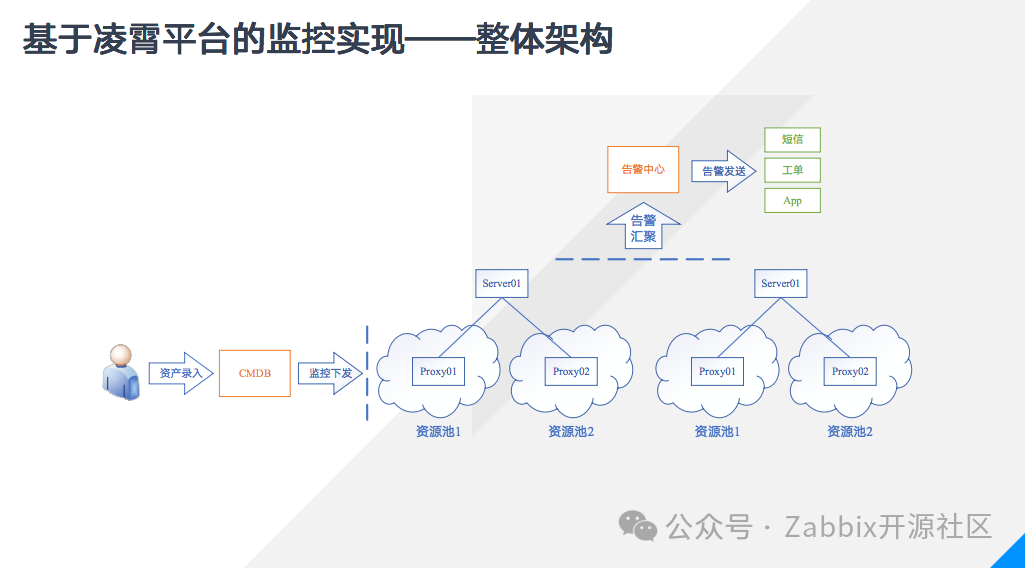
当有新设备入网时,集成人员准备好网络环境、设备资料,在设备上完成snmp配置;Zabbix系统管理员完成proxy的部署和群组创建等准备工作;维护人员在CMDB中录入信息,平台进行规范稽核后完成录入,实现主机的创建和关联对应模板,这样三路并进,全部完成之后新设备的监控就完成了。通过这样的方式,首先极大的提高了工作效率,可以一次性下发大量的主机,迅速完成扩容设备的监控纳管;第二,通过CMDB确保了资产的准确,资产录入是在一张excel表完成,表格的设计原则是”尽量避免人工填写、尽量避免重复信息“,一些相对固定的字段比如厂家、型号,采用下拉表格的方式进行选择,尽可能避免人工填写可能导致的错误,而设备的名称也有明确的规范,包含了平台、机房、机柜等物理信息,通过多个字段拼接合成,确保命名不会重复,第三,监控下发过程全部由平台完成,确保不会出现人工操作的比如遗漏和错误,我还将snmp无数据设置为了告警,确保监控项的有效性,第四,取消了普通用户Zabbix账号的操作权限,所有增删修改操作全部通过系统执行,每一步操作都有记录留痕,权责分明。
除了Zabbix之外,我们还有其他的告警源,例如天翼云、prometheus、内部业务以及外部客户的监控系统,如果在每一个系统中进行告警的处理会导致管理的碎片化,因此告警被统一汇聚到凌霄平台,实现告警的预处理和发送。首先实现了统一的大屏展示,对于值班人员接到告警工单时了解全局状况是十分重要的;第二可以对告警进行一些预处理,目前实现的主要是告警压缩和关联预警。在日常工作中有时会遇到告警风暴,比如网络问题导致的大量ping不可达,比如某服务器宕机导致的多个相连交换机端口dwon,在平台上可以自定义告警归并策略,例如按照相同主机、按照相同告警归并,以及根据拓扑将对端相同的交换机端口down告警合并,这样可以有效压缩告警数量,减少重复告警的打扰。除了归并之外,还可以进一步进行故障面的分析,实现告警到业务之间的关联预警,例如宿主机宕机会导致承载的虚拟机重启,此时平台会自动给业务维护人员发邮件通知,尽量减少业务中断时间。告警经过预处理之后就通过各种媒介进行发送,目前采用的是短信、工单和即时通讯工具三种方式,三种方式各有利弊,因此需要相互补充。短信最为便捷,但是由于缺乏管控手段,也容易被忽略和遗忘。工单会通过语音外呼通知维护人员直至接单为止,确保通知到人,实现了告警的处理留痕和闭环管控,为了减少夜间工单对维护人员的打扰,工单被分成三等,第一等是24小时立即派单,针对的是可能大规模影响业务的重要告警,二等是24小时延时派单,延时期间如果告警恢复了则不派单仅仅短信通知,针对的是可能自恢复的次级告警,三等是仅仅白天派单,夜间工单会延迟至早晨补派,针对的是硬件故障一类无需立即处理的告警。除了告警工单之外,例如带宽利用率偏高等不直接影响业务、但是长期下来可能形成隐患的问题,会通过隐患工单派发给维护人员。以上两种传统方式由于依赖于电信内部系统存在隐患,因此增加了企业微信和钉钉发送群消息作为补充,即时通讯软件消息可以非常方便在电脑上处理故障,另外还具备一定的二次开发能力。
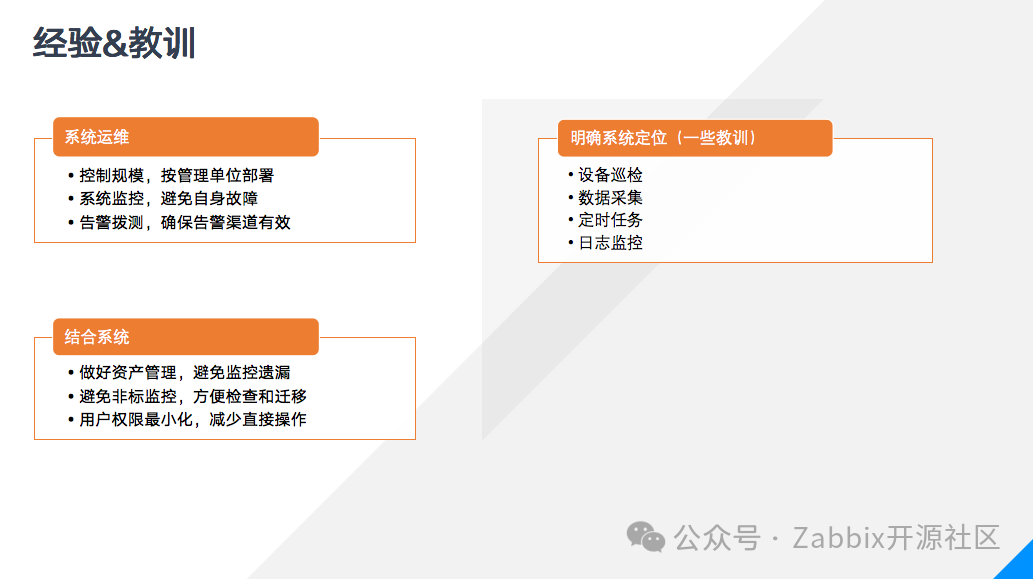
Zabbix的使用在官网手册上已经有了很详尽的介绍,下面和大家分享一下我的经验和教训。一套原生的Zabbix就只适合一个中小规模的监控场景。单套Zabbix有其性能瓶颈,最初我们用物理机部署了一套4.0版Zabbix对全省业务做集中监控,尽管物理机性能很强大,但是在8000台主机时就超出了系统负荷,不得不进行拆分,而且涉及部门一多需求就变得复杂,人员、权限的变更也变得难以控制,所以这是我的第一个建议,控制系统规模和范围,把系统限制在一个管理单位之内。第二就是做好系统本身的监控,如果server发生宕机那么是发不出任何告警的,所以最好有另一套系统对server进行监控,这也是我们没有用位于仪征资源池的Zabbix监控仪征资源池,而是另外在吉山建了一套的缘故。第三是确保告警渠道有效,任何系统都不可能保证永不宕机,因此不要把所有的希望都寄托到单一告警渠道上,最好通过多个相互补充,同时再做好告警拨测,比如我们的系统每天早上都会发一条短信、一个工单、一条企微信息,帮助维护人员发现系统问题。如果Zabbix规模很大或者有多套,那么就可以通过一个上层系统去统一管控就很有必要了。在创建监控的时候,尽可能的通过模板而非直接在主机上创建监控项,这样一方面方便复用,另一方面变更需求时只需修改模板。在选择监控方法时,首选通过web即可配置的方法而非需要在proxy或者主机上放置脚本的方式,这样在遇到涉及重装、更换proxy的时候可以避免很多麻烦。最后,严格控制好用户的权限,以免出现用户私自停用主机、停用触发器,甚至修改模板的情况。最后给大家分享一些教训。Zabbix的功能非常强大,但它并不是无所不能,我们曾经做过很多尝试,比如通过ssh监控项进行设备巡检,但是这种方式一来无法灵活控制执行,二来修改密码或者检查执行结果时需要逐台进行查看;我们还尝试过用Zabbix采集数据,通过设置监控项采集例如设备序列号、配置之类的硬件信息,这样做的后果是监控项数量的暴增,甚至于导致最新数据界面无法打开;我们还尝试过用Zabbix做安全扫描之类的定时任务,尝试做业务的日志检查,技术上都可以实现,但是会造成管理的困难,如果维护跟不上,后期就会出现大量失败监控项、无人认领的脚本和文件各种问题。
所以我的建议是明确Zabbix的系统定位,让Zabbix做好自己监控的的本职工作,远程作业有ansible,日志采集有elk,让更专业系统做专业的事,避免职责不清的情况,保证工作的长期有序。
 2024-03-27
2024-03-27
 Zabbix 下载
Zabbix 下载 Zabbix 手册
Zabbix 手册 Zabbix合作伙伴地图
Zabbix合作伙伴地图 成为我们的合作伙伴
成为我们的合作伙伴
 订阅系统登录
订阅系统登录





