 Zabbix 下载
Zabbix 下载 Zabbix 手册
Zabbix 手册 Zabbix合作伙伴地图
Zabbix合作伙伴地图 成为我们的合作伙伴
成为我们的合作伙伴
 订阅系统登录
订阅系统登录案例| 京东基于Zabbix告警治理优化实践长文回顾(含PPT)

许泽明,京东集团SRE。本文整理自许泽明在2021Zabbix深圳大会发表的演讲。
泽明是Zabbix的好朋友,多次参与手册翻译。他介绍京东集团的组织架构、SRE与告警的关系,Zabbix与告警分级、告警自愈、告警大盘、告警报表、巡检机制、值班机制、Chatops、混沌工程、备战演习、阈值方法论,最后给出兄弟部门建议“如何避免背锅”,给个人建议要负责、不要过于“老实”,具有稳定性工程化意识,及4本学习书籍推荐。
同时京东招聘SRE、运维开发相关岗位,感兴趣的可以联系泽明,泽明微信在ppt末页。

https://www.bagevent.com/event/7476982
大家上午好,我是来自京东集团的SRE许泽明,非常荣幸参加本次特殊形式的线上大会,由于疫情管制原因,非常遗憾不能前往。本次分享的主题是关于Zabbix告警与优化实践。
京东集团是一家定位于以技术为本,业务为基,多场景的高增长型互联网公司。我们的运营团队隶属于京东集团的信息化部门,负责对内对外各BG、BU和相关子公司提供园区分支应用系统基础设施等IT解决方案。

1 SRE与告警的关系
图中是主要组织架构,可以看出软件行业是相对标准的分工,SRE团队在其中会与各个团队进行相关的交互,属于一个合作密切的组织。我们的工作主要围绕着SRE的七大方向,自下而上从监控、事故响应、事故复盘、发布与测试、容量规划、运维开发、产品体验。主要介绍2-3层,在告警和事故方面的一些实践。由图也可以看到,告警是构建在监控之上,监控是告警的前提。
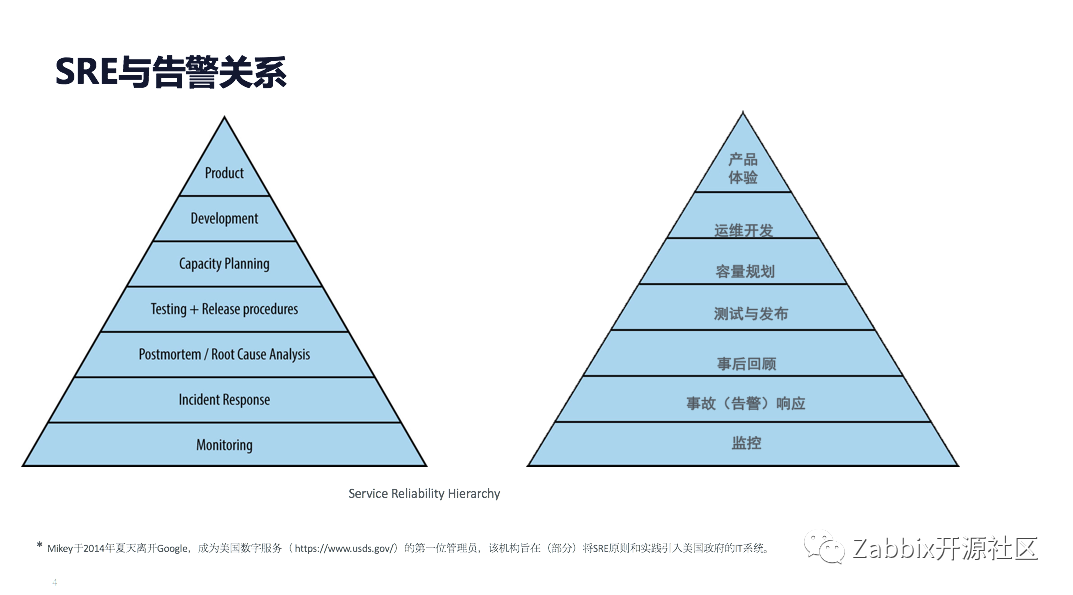
告警是什么及其目的?告警是指的一些重要事件的发生,它迫使你改变你正常的行为,比如说代码的变化,环境的变化,人的操作的变化。正是因为这种不断的变化和混乱,才需要我们快速地发现潜在的异常,做出应急和正确的响应。告警的意义是什么?显而易见,告警主要就是为了解决和提升系统的可靠性来保障这些不确定性,控制相关的故障时间,缩小影响范围。
下面也有一些常见的这种计算公式,比如说我们sra的指标或者可用率。针对告警服务,也规划自己的告警服务的网关。主要是提供了模板配置、多渠道通知、告警策略、故障自愈、CMDB、抑制聚合、告警报表、升级值班、标签管理和ChatOps的功能。
2 Zabbix与告警响应 在告警分级上,参考设置三个级别,然后对应相关的Zabbix告警,通过不同的渠道进行告警分发。在告警响应方面,流程相对标准,主要是通过基本模板的配置生成相关的告警规则。通过告警推送给自愈网关和告警的网关,通过规则匹配相应的自愈策略和人工的处理告警。至于未恢复的告警,我们会生成相关的工单以推动告警的建设。 在告警处理中主要会面临开发跟运维这两种交集,因为这种职责的不确定性也产生了一些影响,所以SRE需要去不断的平衡跟优化这个过程,来使告警处理能达到一个理想的状态。
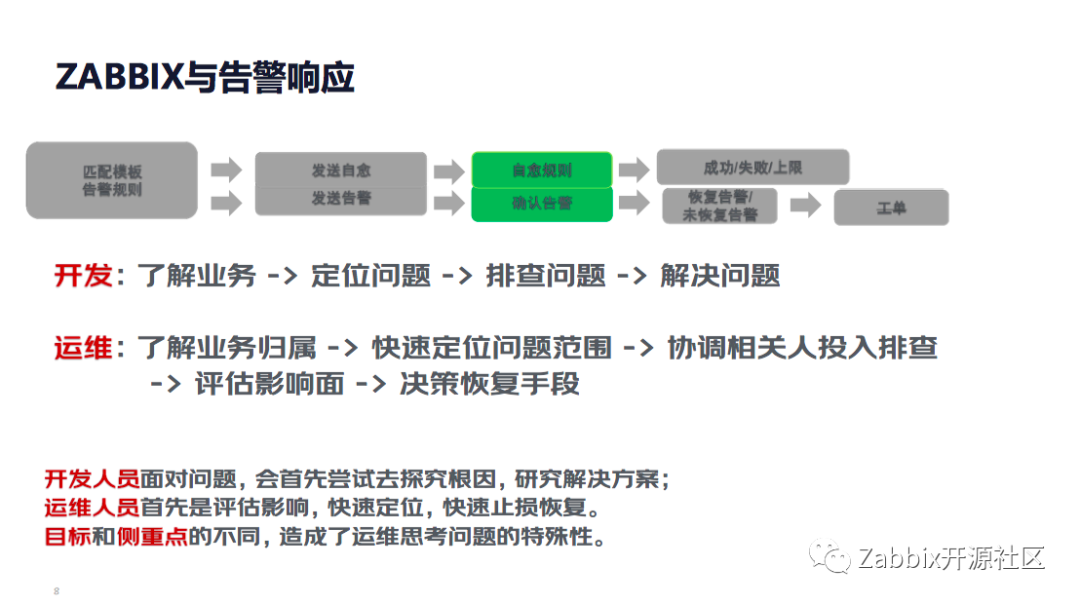
在Zabbix告警的接触方面,这张图是告警处理的看法。当工程师收到相关的告警消息之后进行查看,会打开一个页面,这个页面提供了相关CMDB的资产信息、配置信息、人员信息、监控指标数据和告警当天处理的情况,然后可以去进行相关操作类的触发,如创建工单、告警静默、告警升级,批量确认告警等操作。
3 Zabbix与CMDB的集成、告警升级、告警静默、告警合并、告警工单 Zabbix与CMDB的集成主要是将CMDB的数据和Zabbix进行打通,把人员、资产、节点分组信息进行绑定。比较有特点的是我们将监控组基于机房和集群的字段维度进行了构建,来解决Zabbix在多维数据抽取方面的一些难度。 告警升级也是参考着Zabbix的策略进行开发集成,主要是通过相关的升级项来逐级进行升级人扩展,来扩大告警范围,直到有人关注为止,防止遗漏。稳定性工作是否有能有效执行,其实很大程度上也需要上级跟团队成员的理解,还有制度的保障密不可分。 告警静默主要是为了做快速的告警屏蔽,可以理解成是Zabbix告警维护的一个机制。原理上其实主要是通过redis key加TR和salary来实现静默时间的触发,通过联动Zabbix维护实现。 告警合并主要是为了避免海量告警的干扰,还优化用户的体验,对大量的告警进行合并和预警升级操作,目前也是运用了redis key counter的方式来进行触发,通过key来合并告警内容。 告警工单主要是为了解决线上一些遗留的告警,我们把一些需要协同和流转的事情,通过创建工单来进行相关的操作,是处理线上遗留告警的一种治理手段。 4 故障自愈
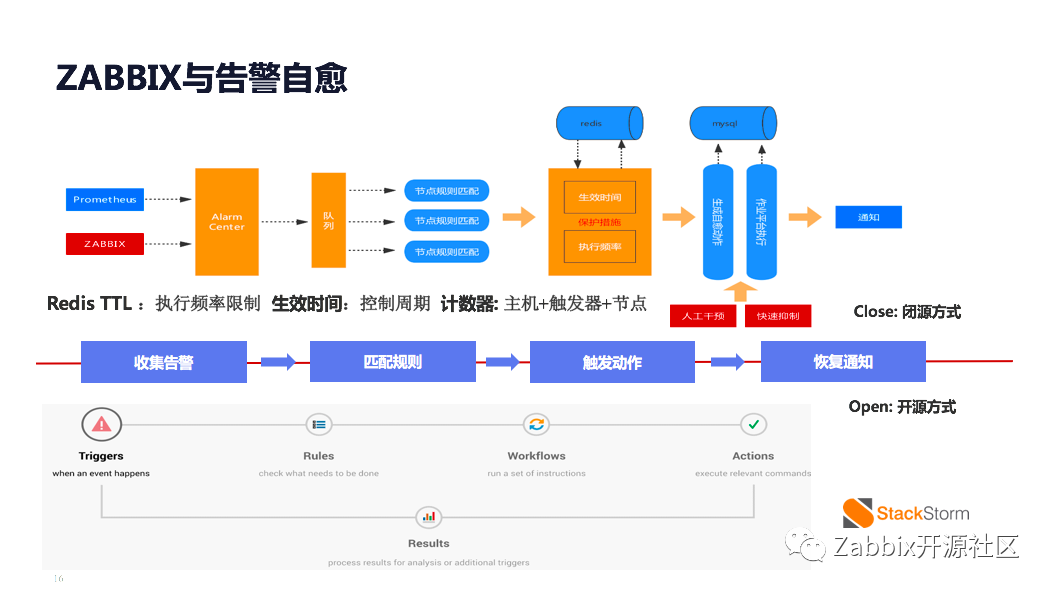
故障自愈是相对重要的,故障自愈主要是通过告警事件去驱动自动化的规匹配规则来进行相关脚本和API的自动修复,是一种事件驱动架构的衍生形态。通俗的理解,故障自愈就是告警规则的规则,可以理解为告警规则的增强版,是提升效率和缩短故障时间,增强自动化水平的一个重要组件。所以这里我会展开两张专门介绍。
对于故障自愈的选型,常见的就两种方式,第一种是开源的,类似于Storm来进行开箱部署,少量人力的代码投入即可进行接入。第二种方案就是闭源的自研方式,我们因为需要去对接一些内部的系统和内部的一些流转机制,所以我们做了内部的集成。
在整个自愈流程中基本上会抽象为4个步骤,一就是接入告警事件源,二是匹配你的咨询规则,三是触触发相应的照顾作业,四是进行相关的通知和人工的二次确认。基本也符合了正常的一个自愈或者事件发展的过程。
简单介绍一个例子就是我们在处理物理机故障的自愈修复的过程。通过相关的资源配置,关联我们右侧的一些自愈脚本进行相关的服务,自动下线,标记故障机,提报相应的硬件维修系统的流程,来实现自动化的故障处理,降低和释放了非常多的人力。
5 告警大盘、告警报表、告警巡检、告警值班
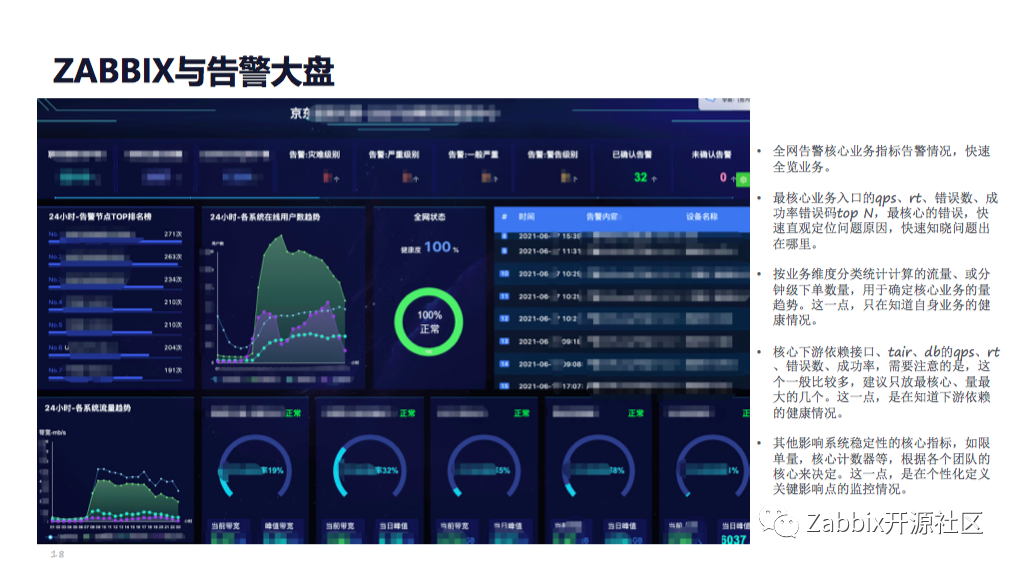
告警大盘的功能主要是为了呈现对全网所有的告警跟核心业务和全局态势的可视化的信息大盘,是我们日常和大促期间备战的主要首选工具。
从图里面可以看出,主要是放置了一些核心的指标,如量、率、比这些指标,这些指标可能每个公司都要根据自己的业务进行适当的调整,适合自己的最佳场景。
告警报表是针对全网的告警数据的分析,主要是帮助业务运维和研发人员进行日常的巡检操作,及时了解线上的稳定性和潜在的业务风险,进行及时的修补。
告警巡检也是通过告警报表在技术上和管理上进行两种维度的结合,系统上主要是通过每日或者每周的告警报表来推送给相关的负责人,制度上通过周巡检的方式来考核业务是否达标。
告警值班,针对告警,还开发了相关的值班系统,主要通过灵活的配置相关值班分组人员,来打通相关的告警API和相关的日常on call跟工单工作,来保障整个团队可以有效的进行标准化的on call流转。
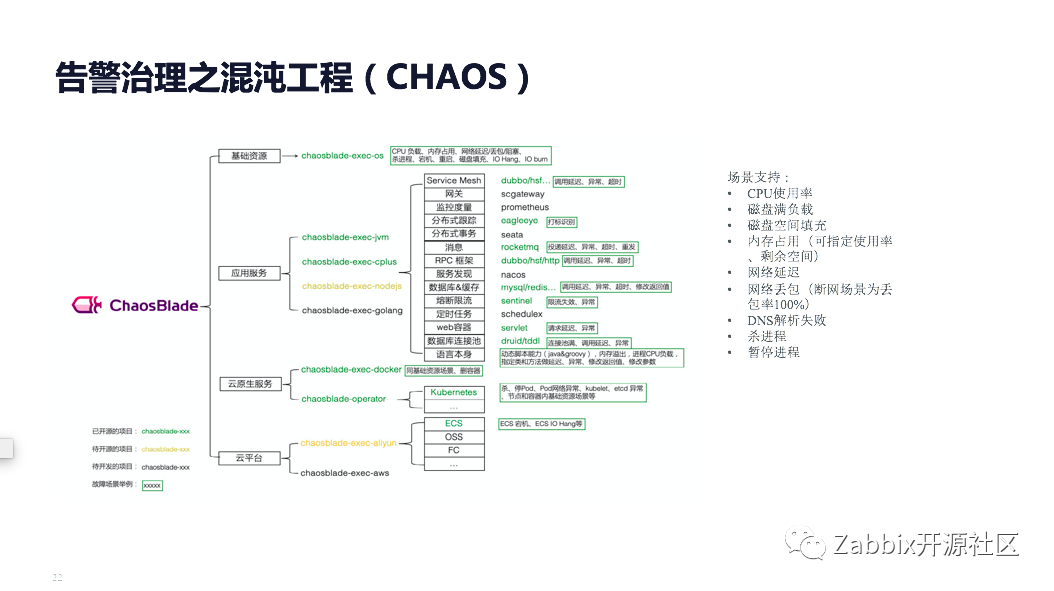
6 ChatOps 告警治理之混沌工程(CHAOS)
引入Chatops的工具,目的是想通过聊天室为渠道来打通人和机器的隔阂,通过对话来实现一些简单的操作。可以理解成类似的智能客服的功能,通过机器人的方式来引入相关自动化的操作,可以在4个方面进行提升。
公开透明。因为机器人在聊天室中是相对信息平等的,这样就减少了工作中的一些信息壁垒。
上下文共享,是指我们用户之间可以通过相关的信息进行传达,在整个工作中数据是可被追溯的。
移动端友好,是因为是可以通过一些工具做一些简单的在非VPN环境的一些快速操作。
是降低develop和自动化工具门槛的一个重要的手段。
混沌工程引入主要是为了做故障注入和破坏性行为的验证。主要是通过对故障引入的时候,通过监控跟告警数据的信息反馈,判定预案是否是有效的,来提升我们的高可用和健壮性,属于一种故障自驱的方式。
我们内部的混沌工程的系统代号叫响尾蛇。从图中可以看到,可以引入一些如CPU、负载、磁盘等常见的os层面的问题。目前我们还在做故障自愈、故障系统和监控系统的集成对接,来实现整个系统数据的建设。
7 大促备战和演练 大促备战和演练,也是我们在做告警治理跟故障治理的一个重要的方式。因为电商行业的特殊性,我们每年会进行618和双11。在提前备战的过程中,我们就会把相关的系统弱点和一些需要做高可用加固的任务都会建立起来,通过搭出了备战进行相关的高可用提升。大促演练的话是通过一些部门级或者公司级的全链路的故障压测和编办进行的一些故障点的暴露,这样子可以去发现一些木桶效应的问题,进行一些及时止损,对我们来说是非常重要的处理故障的方式。 8 阈值方法论
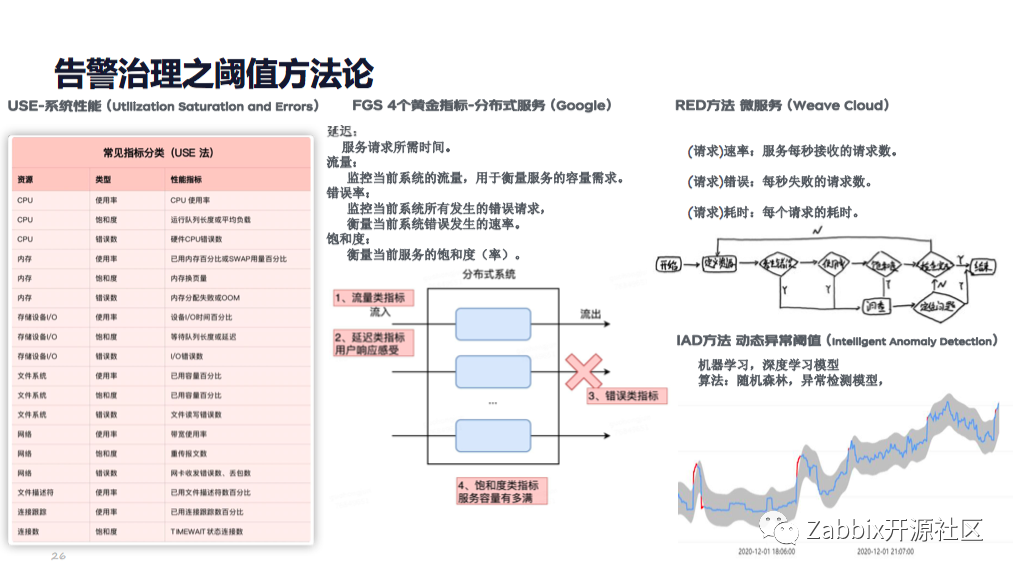
在告警治理方面,一个告警是否合理很大程度取决于告警阈值的配置是否恰到好处。这往往也是一个运维在技术水平高低的重要体现。这里通过提供一些方法论去根据自身业务来找到适合自己的。
1.USE系统性能方法,通过利用率、饱和率和错误率方法来进行。
2.经典的谷歌黄金四指标法,延迟流量、错误率、饱和率。
3.针对于目前主流的微服务的框架,可以引入 RED的方法,对速率、错误率、耗时进行判定。
4.目前更先进的IAD动态阈值方法,通过一些算法的引入来帮助和指导阈值的动态配置,这些都需要相关的专家和团队进行工程化系统化的建设,也非常考验整个技术部门的功底。
9 合作共赢(不甩锅)?

如何支持告警治理合作共赢、共建稳定?在告警治理过程中一定非常需要兄弟部门的配合,因为在大型的系统工程的建设中,任何一个团队和个体都是非常重要的,所以需要上下游的兄弟团队给资源、给空间,帮助我们一同成长。
区分责任,如果没有一个合理的责任划分的边界,都把锅甩给运维,其实是恶性的循环,想必不少的搞运维的团队同事都会遇到甩锅的场景。
10 告警意识所需意识和态度? 第一,他必须是一个相对负责任的人,责任心是第一要位。 第二,原则上最好不要选择新人,因为新人在整个工作中他可能做的都是大家不愿意做的工作,也可能就是很多操作类工作。在一个新人对业务和系统不了解的情况下,去做这样的一件工作,其实是存在着非常大的风险的。所以一般情况下建议还是新人熟悉完整个业务系统之后再去介入,是相对安全的,防止误操作删库跑路的情况。 第三,不要用过于“老实”的人,这里面的老实并不是指的真正的老实人,这里面老实其实是指的是这种吃苦耐劳,但是他缺乏主动思考的人。因为工程犹如大坝,如果缺少主动性思考跟发现问题的人,那么他就会在工作中把这些问题隐藏掉。当一个问题在不断的堆积、扩大,可能在一个不确定的时间内就会爆发出来一个爆发出来。 第四,稳定性工程的意识,因为稳定性工程的意识是关系到每个人或者每个团队整体的建设。所以要格外的注意。 推荐SRE相关学习资料,同时我们也在招聘相关的运维开发跟SRE岗位,如果有相关感兴趣的朋友可以加我微信。




扫码获取大会PPT
备注“使用Zabbix年限+企业+姓名”
进入交流群,4000+用户已加入
一个人走得快,一群人走得远

 2023-04-26
2023-04-26






